
Imagine you collected network data among six nodes:
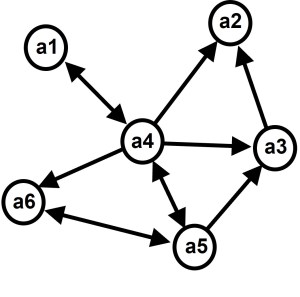
One simple and efficient way to store this directed network is by using a csv (comma-separated values) file. A csv file is a plain text file and yet can easily be opened in spreadsheet programs, such as Excel.
When storing network data in a csv file, there are three major types of formats that can be used: a matrix, edgelist or nodelist format.
The Matrix Format
The matrix format contains the names of the sender on the left (first column) and the names of the receiver of a tie at the top (the first row). For a one-mode network, the names in the first row and the first column should be the same and the order should be the same, as the example below shows.
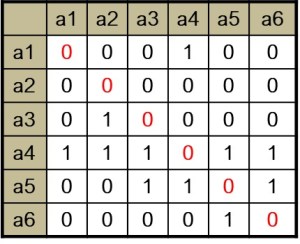
Note that the diagonal entries (in red) represent self-nominations (loops), and these are often not relevant in network data, as we are not interested in whether a person is friends with him/herself.
When the network data contains values, such as in the network below, these will be represented in the respective matrix cells.
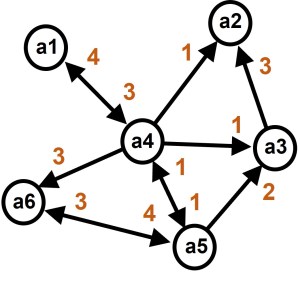
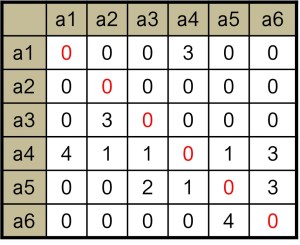
Cells can also contain missing data to represent that the network information is unknown. This should be represented by a unique code, such a “-999” or “NA”.
For an undirected network, the matrix will be symmetrical, meaning that the value from, for example, a1 to a3, will be the same as the value from a3 to a1.
For a two-mode network, the row names and column names will be different as links are only possible between the two distinct modes (e.g., people and parties, where the tie represents who was present at a specific party).
The matrix format is most efficient if the network is dense (i.e., many cells contain values other than 0).
The Edgelist Format
The edgelist format stores only the ties that are present (i.e., with non-zero values). Each non-zero directed tie (edge) is stored in a separate row, where the first column contains the name of the sender and the second column contains the name of the receiver of the tie. In the example below, we can see that there is a tie from a1 to a4, but no tie from a4 to a1 as the dyad (a4, a1) is not present.
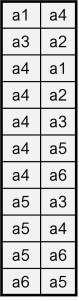
Such a format is efficient when the network has a low density and when it is large.
For a one-mode network the names in the two columns should be overlapping, while in a two-mode network the names in the first column should represent one mode (e.g., people) and the second column should contain distinct names (e.g., events).
Be aware that isolates will not automatically appear in the dataset, as they will not send, nor receive any ties. You might want to store such isolates at the bottom first column, i.e. as sender without receiver or in a separate file, depending on how you will import these later.
For valued networks, such as the network above, you will need to add a third column with containing the values for each edge.

A third column can also be used to indicate missing data. For dichotomous networks you will need to add a “1” for a present tie, and an “-999” or “NA” for missing information (still ignoring the “0” ties).
Note that for undirected networks, you only need to add a tie once, i.e., i to j implies a tie from j to i.
The Nodelist Format
To generate a nodelist format, create a separate row for each unique node, where the node name of the sender is defined in the first column, and the receivers are then listed in the subsequent columns.
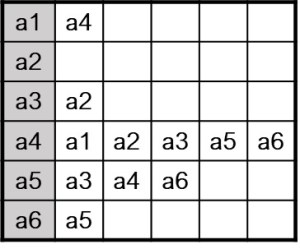
All nodes in a one-mode network should be present in the first column, so that those nodes without any outgoing ties (such as node a2) will only have its name in the first column, and empty cells in the next columns. This means that isolates will still be contained in a nodelist dataset.
For two-mode networks, the first column contains the nodes of one mode (e.g., people), and the subsequent columns contains the names of the nodes of the second mode (e.g., events). This means that the names in the first column should be distinct from those in the subsequent columns.
For a network with tie values, as above, two separate files are needed, with one file containing the names of the sender in the first column and the receivers in the subsequent columns and a second file containing again the names in the first column and the values of the ties in the subsequent cells. Note that the values should be in the corresponding cells (for example the 3 in 6th column of row 4 indicates the strength of the tie from a4 to a6).
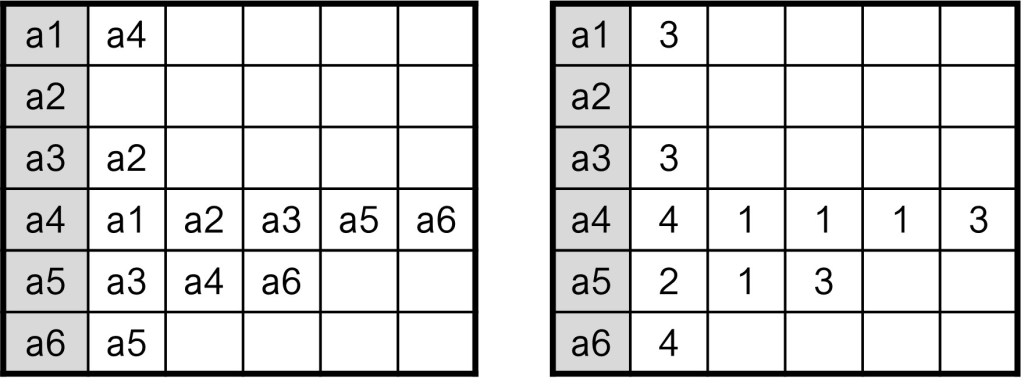
This approach of a second file can also be used to add missing values, where the values would either be “1” or missing (as indicated by for example “-999” or “NA”).
